If QM is hard, it shouldn't be because we're mixing up concepts that are distinct but go by the same name. The below is an attempt to prevent you from falling into some traps that I did.
What is phase?
Phase is one of the most important concepts in QM, and yet, when you're starting to learn QM, it can be terribly confusing. That's because what the word means depends on the context. Even people who should know better sometimes confuse it!
Let's look at what it can mean for light.
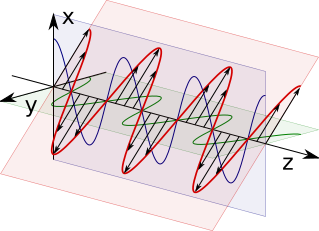
Recall that light is an electromagnetic wave. Light propagating in some direction will carry an electric field and a magnetic field, perpendicular to each other, and both perpendicular to the direction of travel.
$E$ represents the electric field, and $B$ the magnetic field. The lines represent the direction and strength of the field. Note how $E$ is vertical, moving sinusoidally from up to down and back. Also note how $B$ is doing the same thing but horizontally. We call this
linearly polarized light for obvious reasons.
Let's look at how we represent this quantum mechanically. Sorry, some math will be involved here.
We will let the vector $|x\rangle$ represent horizontal polarization (using
Dirac bra-ket notation), and $|y\rangle$ represent vertical polarization. Because the polarization is restricted to the y-z plane, it's two dimensional, and we only need two basis vectors. (We can also write these as (1, 0) and (0, 1) in coordinate form. Similarly, the vector $|x\rangle + |y\rangle$ can be written as (1, 1).)
We will let $|\psi\rangle$ indicate the photon's polarization state (i.e., its
electrical field direction). In the above diagram, we have:
$$|\psi\rangle = |y\rangle = (0, 1)$$
But recall that in QM we use
complex vectors, not
real vectors. This just means that the components can take on complex values. For example:
$$|\psi\rangle = i|y\rangle = (0, i)$$
What does this correspond to physically? Recall that a complex number can be written as $re^{i\phi}$, where $r$ is the "norm" (or "length") and $\phi$ is the "phase."
Now note that $i = e^{i\pi/2}$ (corresponding to the line pointing up in the above picture, where the angle is $\pi/2 = 90°$). That is, it has a phase of $\pi/2$. To understand what this means physically, imagine the EM diagram with the waves shifted left by $\pi/2$ -- that is, one quarter wavelength backward (since a whole wavelength is $2\pi$). So you can think of the phase $\phi$ as the position where the wave "starts." This would still be a linearly (in particular, vertically) polarized wave, but one that started at its maximum position instead of at zero.
How about this state?
$$|\psi\rangle = \frac{\sqrt{2}}{2}(|x\rangle + |y\rangle) = (\frac{\sqrt{2}}{2}, \frac{\sqrt{2}}{2})$$
This looks a little scarier, but notice that the $\frac{\sqrt{2}}{2}$ is just there to normalize the vector so that its length is one. That is, it's just a scaled version of $|x\rangle + |y\rangle = (1,1)$.
This seems to indicate that the light is polarized in
both the x and y directions. And indeed, you could call it diagonally polarized light.
Now the
very important thing to note about the picture above is that the green and blue squiggles are
not the $E$ and $B$ fields. They are just the x- and y-components
of the $E$ field.
Notice how they touch the z-axis at the same time. In other words, they are zero at the same time. They also reach their maxima and minima at the same time. Of course, in this particular diagram they both start at their maximum instead of zero, so they
both have phase $\pi/2$:
$$|\psi\rangle = \frac{i\sqrt{2}}{2}(|x\rangle + |y\rangle) = (\frac{i\sqrt{2}}{2}, \frac{i\sqrt{2}}{2})$$
Also notice that for
any phase, as long as the components both have the
same phase, the light will be diagonally polarized. Another way of saying it is that their phase
difference (or "relative phase") is zero. Also note that if their phase difference is $\pi$ so that one reaches its maximum as the other reaches its minimum, it will be diagonally polarized but in the other direction (i.e., up and to the left instead of up and to the right).
What about if the x- and y-components are out of phase by $\pi/2$? That's a little harder to visualize, but this picture should help you see what's going on when one direction reaches its maximum (or minimum) a quarter phase after the other:
Notice how the vertical arrows peak a quarter wavelength
later than the horizontal ones. This is called "circularly polarized" light, and can be expressed as:
$$|\psi\rangle = \frac{\sqrt{2}}{2}(|x\rangle + i|y\rangle) = (\frac{\sqrt{2}}{2}, \frac{i\sqrt{2}}{2}) = \frac{\sqrt{2}}{2}(1, i)$$
The
relative phase is $\pi/2$. As long as that's true, it will be circularly polarized (in the clockwise direction). In the above, the phases were 0 (because $e^{0i} = 1$) and $\pi/2$ ($i = e^{i\pi/2}$). They could also have been, say, $\frac{3\pi}{2}$ and $2\pi$:
$$|\psi\rangle = \frac{\sqrt{2}}{2}(-i|x\rangle + |y\rangle) = (\frac{-i\sqrt{2}}{2}, \frac{\sqrt{2}}{2}) = \frac{\sqrt{2}}{2}(-i, 1)$$
(Noting that $e^{\frac{3\pi i}{2}} = -i$ and $e^{2\pi i} = 1$).
Also notice that if the phase difference were $-\pi/2$ instead of $\pi/2$, then that would correspond to the counterclockwise direction:
$$|\psi\rangle = \frac{\sqrt{2}}{2}(i|x\rangle + |y\rangle) = (\frac{i\sqrt{2}}{2}, \frac{\sqrt{2}}{2})$$
Phase shift
This brings us to two meanings of "phase shift."
1. We can shift
both of the components' phases by some amount, so that their
relative phase does not change:
$$(x, y) \Rightarrow e^{i\phi}(x, y)$$
Recall from the previous section that as long as the relative phase doesn't change, the polarization doesn't change. If it was circularly polarized, it will
stay circularly polarized, though it would start (and of course continue) at a different angle.
2. We can shift
one component only:
$$(x, y) \Rightarrow (x, e^{i\phi}y)$$
Thus
changing their relative phase. For example, if the relative phase changes from 0 to $\pi/2$, this corresponds to a change from linear to circular polarization.
The second definition is the one
most commonly used, because changing relative phase results in a physically distinct system. So maybe you're really used to that definition, and then you come across this (
Wikipedia, and many other sources):
"Light waves change phase by 180° when they reflect [off a mirror]."
Well, you can test for yourself that polarization doesn't change when light reflects from a mirror. That's because they're using definition one! Their relative phase doesn't change!
If you were smart, you'd quickly figure that out. But if you're me, you might resign yourself to never understanding anything about QM!
To make things worse, as I was learning this, I came across the blog of someone who "worked as a physicist at the Fermi National Accelerator Laboratory and the Superconducting Super Collider Laboratory," who explains that what's changing is the relative phase of the $E$ and $B$ fields:
The circularly polarized wave can be expressed as two linearly polarized waves, shifted by 90° in phase and rotated by 90° in polarization. If you pick some direction to measure the fields along, the components of E and B along that direction have a 90° phase shift with respect to each other. A phase shift of 90° means that as E peaks B becomes zero, and as B peaks E becomes zero.
As far as I can tell, this is just wrong.
The other other meaning of phase
One of the first experiments you come across when hearing about QM is the famous Double Slit experiment. Recall that the interference pattern at the wall is explained by waves adding up or canceling out whether they are "in phase" or "out of phase."
Which phase are we talking about here? To explain it carefully would require some heavy-duty math, so this will be a gross oversimplification.
Above, the state vector was two dimensional, corresponding to the two possible directions of polarization. But the
location of a photon can be
any point in 3D space. So the state vector corresponding to a photon's position is (uncountably) infinite-dimensional. We call this state vector the "wave function." It's not terribly convenient to write out uncountably many components, so sometimes you see it depicted by a diagram:
If it hurts your head to think of this as an infinite-dimensional vector (where each point on the x-axis is a basis vector, and the height is the corresponding component -- and we pretend it is real-valued because it is hard to draw a complex height), you're not alone. If you want to understand the math,
have at it.
Because light is a
plane wave, the
formula for its wave function is given by:
This formula tells you the (complex) value for the components of the wave function at distance $r$ and time $t$ (with amplitude $A$). Ignoring time for a moment, the form $e^{ikr}$ tells us that it's a complex number that's "rotating" according to $r$. (See the circle picture near the beginning.)
Light is effectively being emitted from two slits, and (almost) any point on the screen has a different distance ($r_1$ and $r_2$) from those two slits. Thus, the two waves are at different points in their evolution, sometimes canceling out and sometimes adding up.
So which meaning of phase is being used here? In the previous section we were talking about the phases of different components of the same state vector. Here we're talking about contributions to the same component (the position) from different paths. Seems like a different usage to me.
Again, if you were reading all this stuff by yourself, it would be pretty hard not to become terribly confused.
But wait, there's more!
Lest you think that's the end of the difficulties, consider the usage of the word "length" above. I used it in two different ways. A single complex number $c$ can be written as:
$$c = re^{i\theta}$$
In this form, $r$ is called the
norm. More commonly, it's called the
modulus or the
amplitude. But
amplitude can refer to three different things here:
- The "key innovation" of QM is that we use "probability amplitudes," sometimes called "complex amplitudes." These refer to the complex number ($c$) itself.
- But complex numbers themselves have "amplitudes", usually referring to $r$ above.
- Most confusingly of all, some authors use it to refer to $\theta$! ("The argument is sometimes also known as the phase or, more rarely and more confusingly, the amplitude")
To recap, a complex number $$c = re^{i\theta}$$
is an "amplitude," but it also
has an amplitude, which can refer to either $r$ or $\theta$. One wonders if some day they'll use it to refer to $i$ and $e$, too.
Further, when we have a vector $v = (x, y) = (r_1e^{i\theta}, r_2e^{i\phi})$, we just called $r_1$ the "norm" of the first component. But, like all vectors in a normed vector space, $v$ itself has a norm (the thing you normally think of as a vector's length).
People also fall into the trap of thinking of a single complex number as a pair of real numbers. This makes it impossible to reason about pairs of complex numbers. So please, don't do that.
Summary
QM is hard, but in part that's because it's easy to become confused by terminology and concepts which look the same or similar. As Scott Aaronson points out:
http://www.scottaaronson.com/democritus/lec9.html
"Today, in the quantum information age, the fact that all the physicists had to learn quantum this way seems increasingly humorous. For example, I've had experts in quantum field theory -- people who've spent years calculating path integrals of mind-boggling complexity -- ask me to explain the Bell inequality to them. That's like Andrew Wiles asking me to explain the Pythagorean Theorem.
As a direct result of this "QWERTY" approach to explaining quantum mechanics - which you can see reflected in almost every popular book and article, down to the present -- the subject acquired an undeserved reputation for being hard. Educated people memorized the slogans -- "light is both a wave and a particle," "the cat is neither dead nor alive until you look," "you can ask about the position or the momentum, but not both," "one particle instantly learns the spin of the other through spooky action-at-a-distance," etc. -- and also learned that they shouldn't even try to understand such things without years of painstaking work."